Pandas Indexing Primer

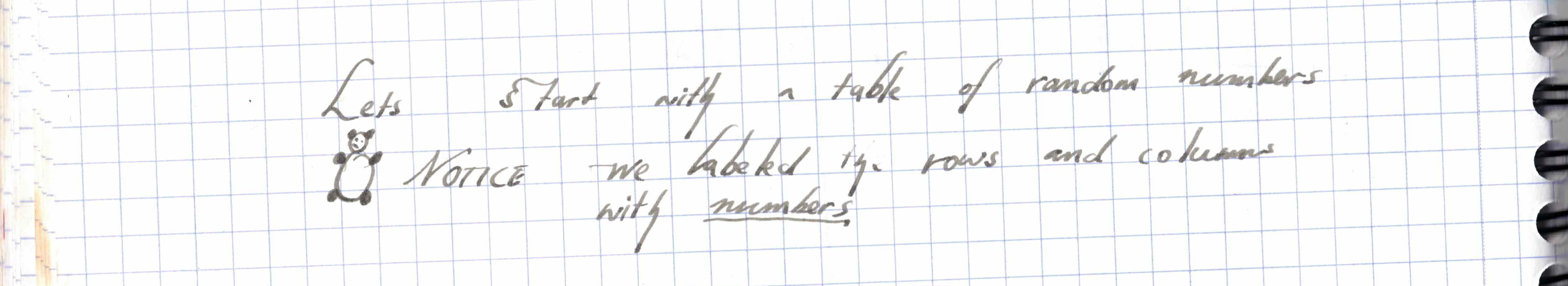
SQLite and Pandas quick intro

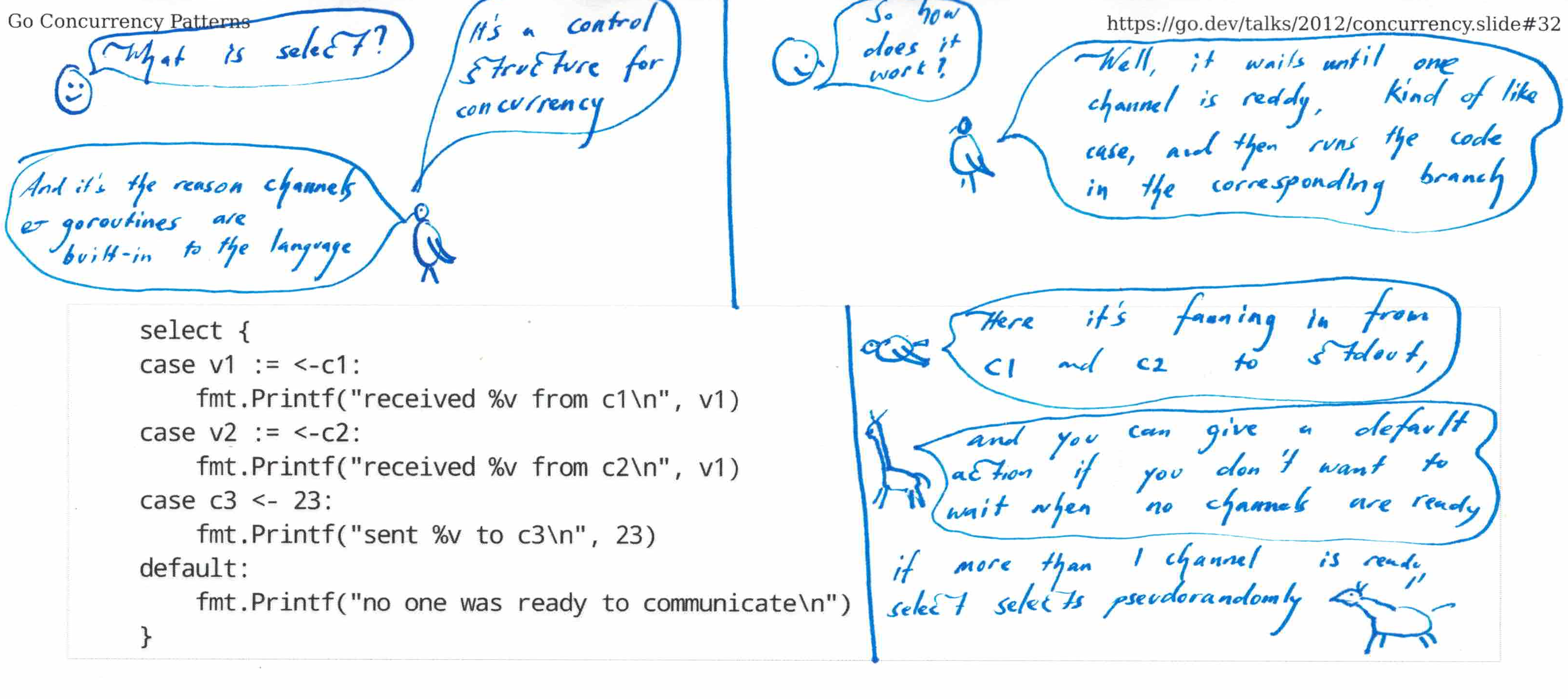
Select is switch/case for concurrency!
Go versus C declarations

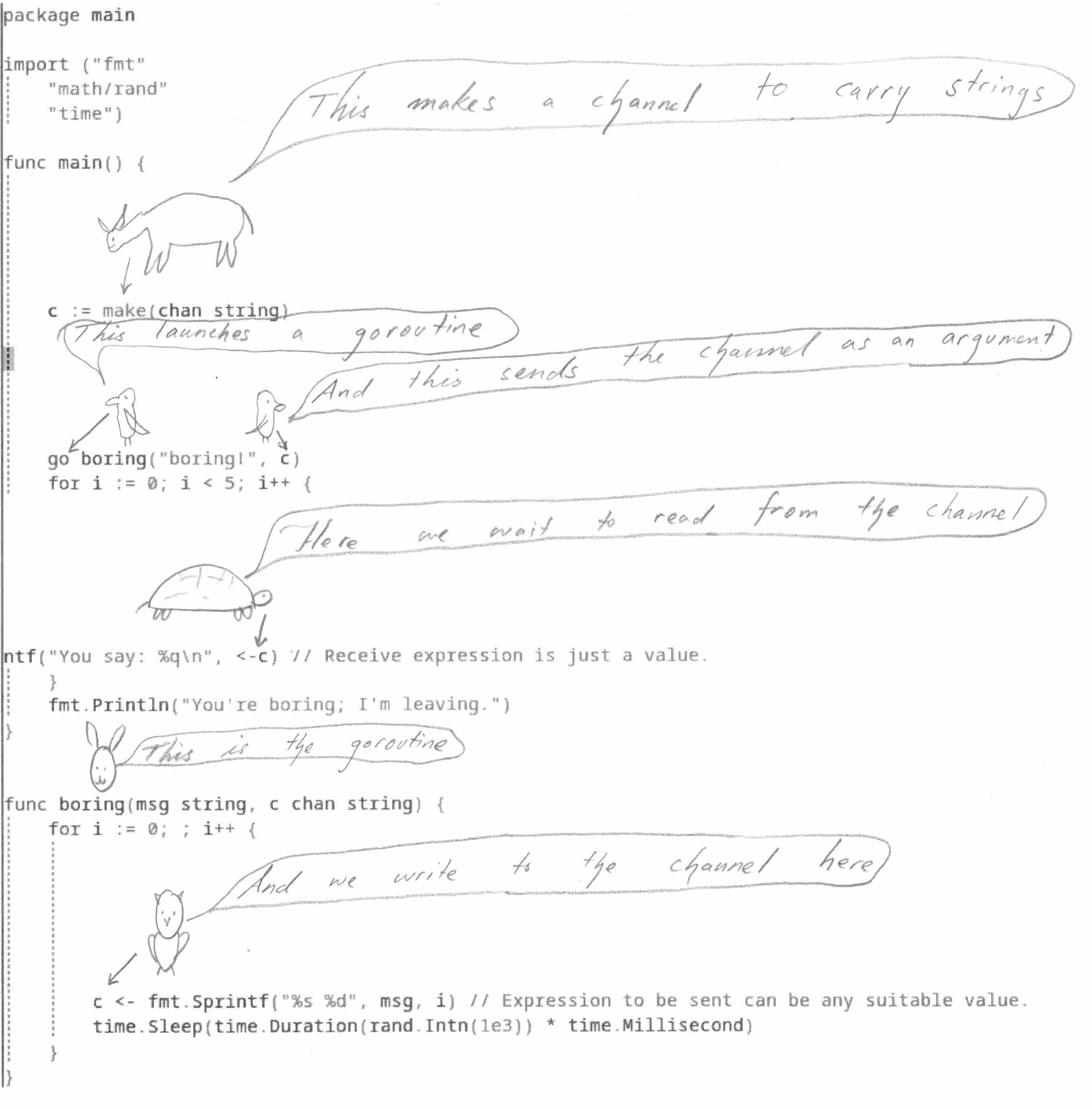
Goroutines and channels - simple!
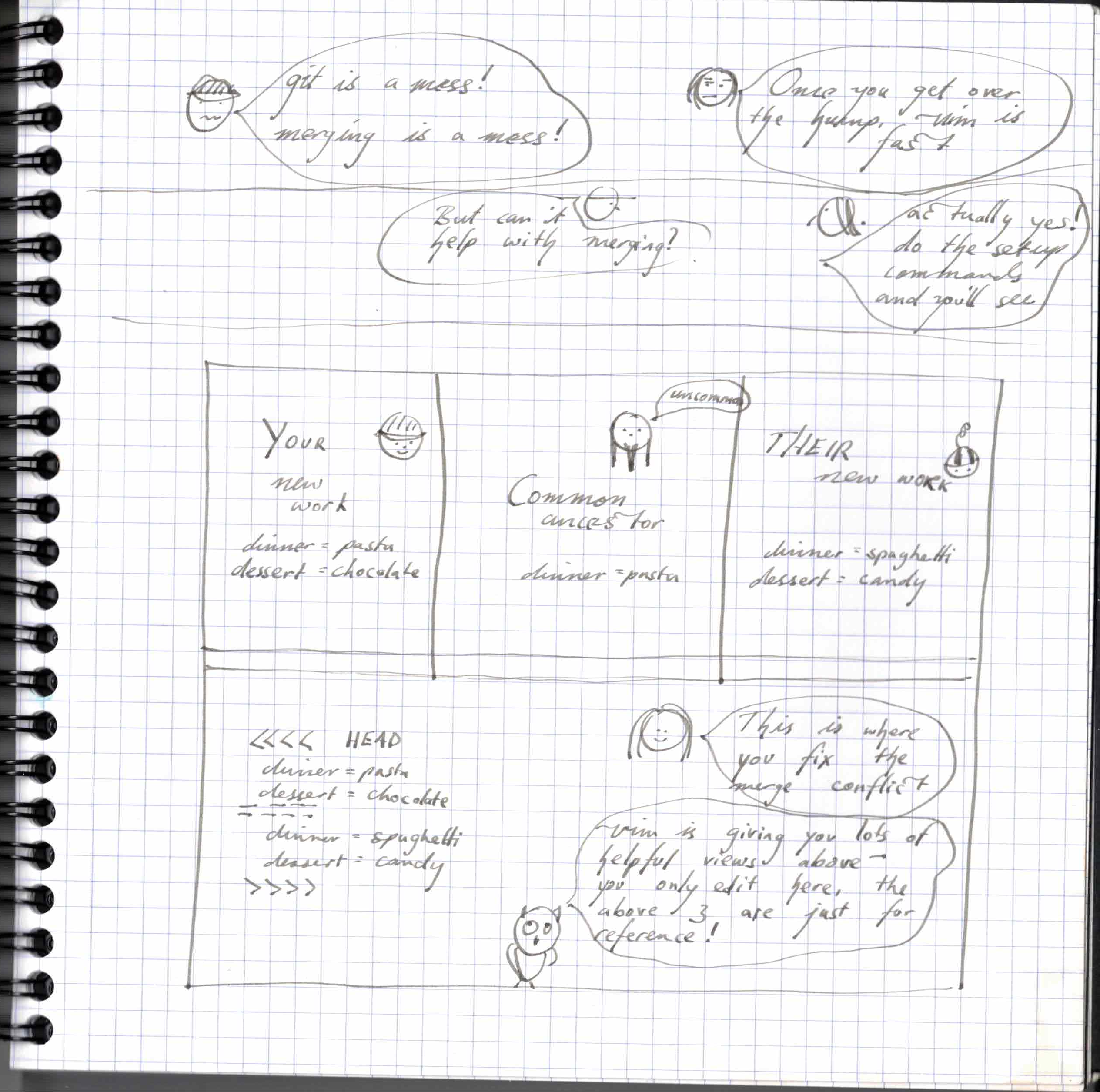
wwhhhaattt vim 4 panel git merge???
Need a decently priced rum?
Hamilton 86 is Guyanese rum without added sugar. Sipping, it opens a clean, straight slight burn, smooth, then we find the caramel, tobacco, smoke, really a nice rum and well priced.